前言
本文是 Flink SQL 系列中的一篇,更多文章请关注Flink SQL 系列文档。
内容全部是原创,如有错误,欢迎铁汁们指出。另外,未经同意,不得转载。
Plan 重写
全局 TopN
全局 TopN 有两种写法,比如:对全网商家按销售额排序,计算出销售额排名前十的商家。有如下两种写法:
写法1
1 | SELECT shop_id, shop_name FROM shop_sales ORDER BY sales DESC LIMIT 10 |
写法2
1 | SELECT shop_id, shop_name, rownum |
分组 TopN
对全网商家根据行业按销售额排序,计算出每个行业销售额前十名的商家。分组 TopN 只有 ROW_NUMBER 一种写法。写法如下:
1 | SELECT shop_id, shop_name, rownum |
ROW_NUMBER 写法,优化器的改写规则
分组 TopN 只有一种开窗函数的写法,全局 TopN 有两种写法:一种是 ORDER BY + LIMIT 的写法,另一种是 ROW_NUMBER 的写法。
对于用开窗函数的 TopN 写法,无论是全局 TopN 还是分组 TopN,优化器会做改写,把 OverAggregate 和 Calc 合并后改写成 TopN 算子。
ROW_NUMBER 写法上对应 OverAggregate 节点 和 Calc 节点 (过滤行数),优化器会进行重写,把这两个节点合并,转为 Rank 节点。
对于上面的示例(每个行业销售额前十名的商家),优化器重写流程如下: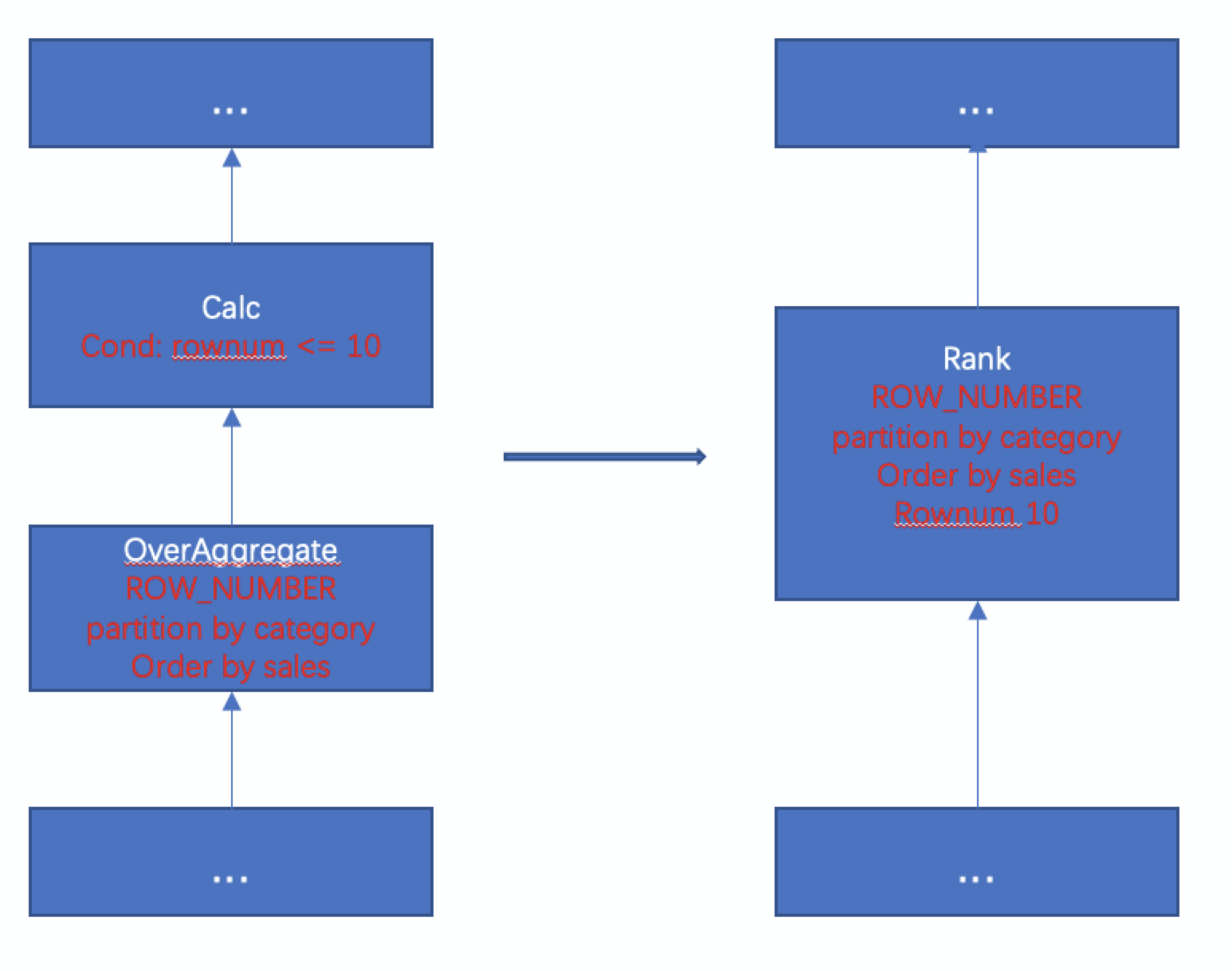
ORDER BY + LIMIT 写法,优化器的改写规则
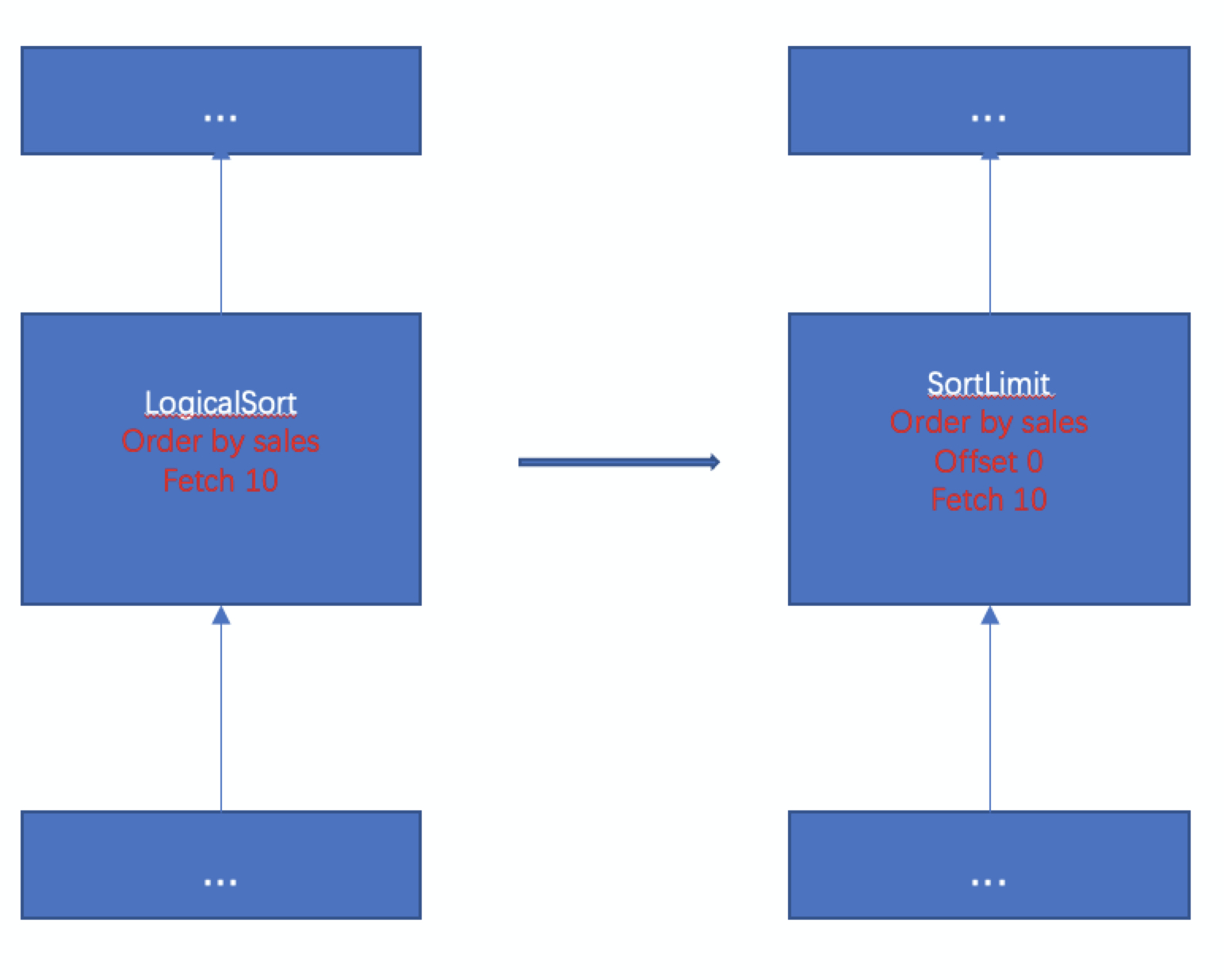
SortLimit 和 Rank 两种节点虽然在 ExecNode 层面是两个不同类型的 Node,但是把 ExecNode转为 Transformation 后,底层的 Operator 是一样的,都会转为三种 TopNFunction 的其中一个。
TopN Function 梳理
Flink 用 ROW_NUMBER 开窗函数用法来表达 TopN,优化器层面会把 OverAggregate 和 Calc 节点转为 Rank 节点。Rank 节点支持5种 AbstractTopNFunction 实现,本文将会深入分析其中三种实现的应用场景和具体实现。
TopNFunction 有五种实现:
- RetractableTopNFunction
输入流是 Upsert 流 或者 Retract 流。是保底算法,性能最差,因为需要在 State 里维护所有的历史数据。 - UpdatableTopNFunction
当输入流满足下面3点要求,可以使用 UpdatableTopNFunction, UpdatableTopNFunction 是对 RetractableTopNFunction 的优化。
a. 输入流是 Upsert 流,不能是 Retract 流。即只能有 Insert 消息和 Update After 消息,不能有Update Before (Retract) 和 Delete 消息
b. 输入流必须要有 Primary Key,且相同 Primary Key 的数据一定分发到相同的并发上 ,即输入流的 Primary Key 包含 Partition Key
c. 输入数据在排序字段具有单调属性,且单调属性与排序方向相反,如 Order by count/count_distinct/sum(非负数) desc。这确保一条记录一旦进入 TopN,后续在这条记录上的更新只会让这条记录的排名靠前,而不会滑落出 TopN 排行榜(因为一旦当前 更新消息导致这条记录滑落出 TopN 排行榜,就需要从历史数据里捞出一条记录补齐 TopN,这样 State 里就不能只存 TopN 数据)。 - AppendOnlyTopNFunction
当输入流中只有 Insert 消息,即是 Append 流,可以使用 AppendOnlyTopNFunction。 - AppendOnlyFirstNFunction
AppendOnlyFirstNFunction 是一种特殊的 AppendOnlyTopNFunction 。为了提高性能,把在时间属性上进行排序的 TopN 转为 AppendOnlyFirstNFunction。 - FastTop1Function
FastTop1Function 也是一种特殊的 AppendOnlyTopNFunction ,当只需要 Top1 时,且不满足转为 Deduplicate 的条件,可以转为 FastTop1Function。
通用的数据结构
TopNBuffer
用来存储一个 Partition Key 下,基于 SortKey 排序后的 TopN 数据。实现基于 TreeMap。
LRUMap
为了减少和 State 交互,LRUMap 缓存 Partition Key 和它对应的 TopN 数据的映射关系。实现基于 LinkedHashMap。
AppendOnlyTopNFunction
内存 Cache 的设计
内存 Cache 里缓存了 PartitionKey 到该 PartitionKey 对应的 TopN 数据。
数据结构是 LRUMap。其中,Key 是 PartitionKey,Value 是 TopNBuffer (PartitionKey 下对应的 TopN 数据),是 State 的数据在内存中的缓存。
State 设计
存储的内容
存储 TopN 记录即可,不需要存储所有的数据
存储格式
1 | MapState<RowData, List<RowData>> //(Key 是 SortKey,Value 是 Records 列表)。 |
State 读写时机
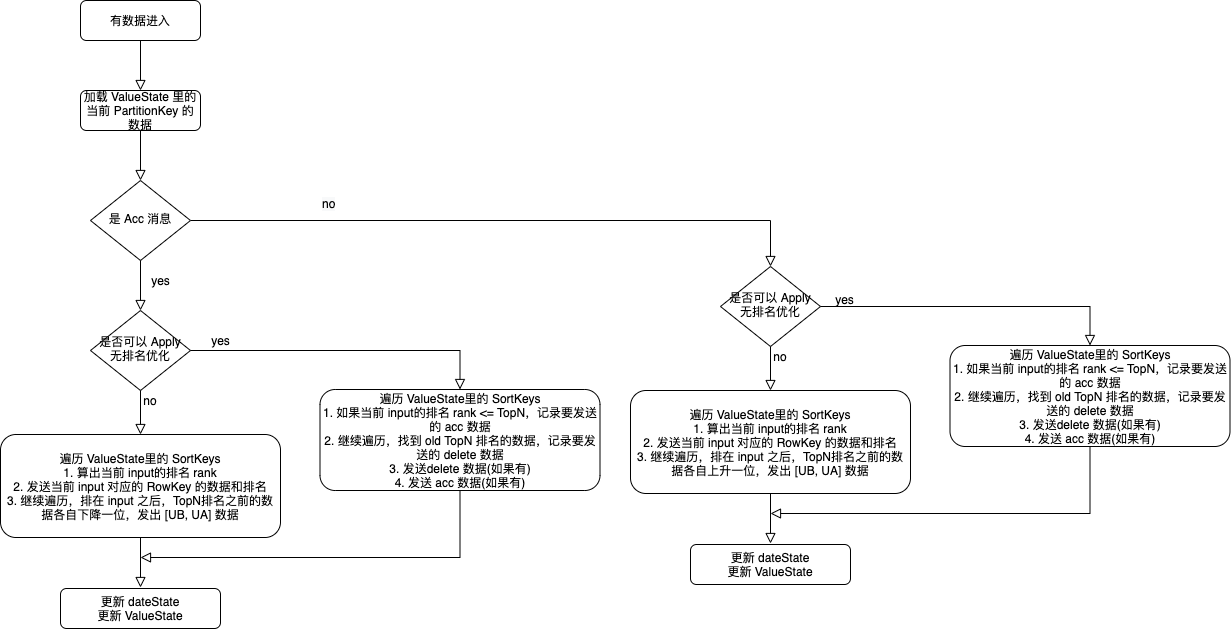
Per Record 和 State 交互,虽然 LRUCache 可以抵消一部分 State get 操作,但是对于引起 TopN 数据发生变化的输入数据,仍然有 Per Record 级别的 State Update 操作,比如在 State 里保存新晋的记录以及删除淘汰的记录。
处理流程
UpdateFastRankFunction
内存 Cache 的设计
内存 Cache 里缓存了各个 Partition Key 下 TopN 数据。
数据结构是一个 LRUMap,Key 是 Partition Key,Value 是该 Partition Key 下 TopN 的数据(是个 Map,Key 是 Primary Key, Value 是 Record),对应到 State的数据在内存里的缓存。
另外,为了提高读写效率,内存里还维护了相同数据的另外一份表现形式,Key 是 PartitionKey,Value 是 TopNBuffer(Key 是 SortKey,Value 是 Records的 Primary Key 列表)。
State 设计
存储的内容
存储 TopN 记录即可,不需要存储所有的数据
存储格式
1 | MapState<RowData, Tuple2<RowData, Integer>> // (Key是 rowkey, Value 是Tuple2.of(record, index in the list of same sort key)。 |
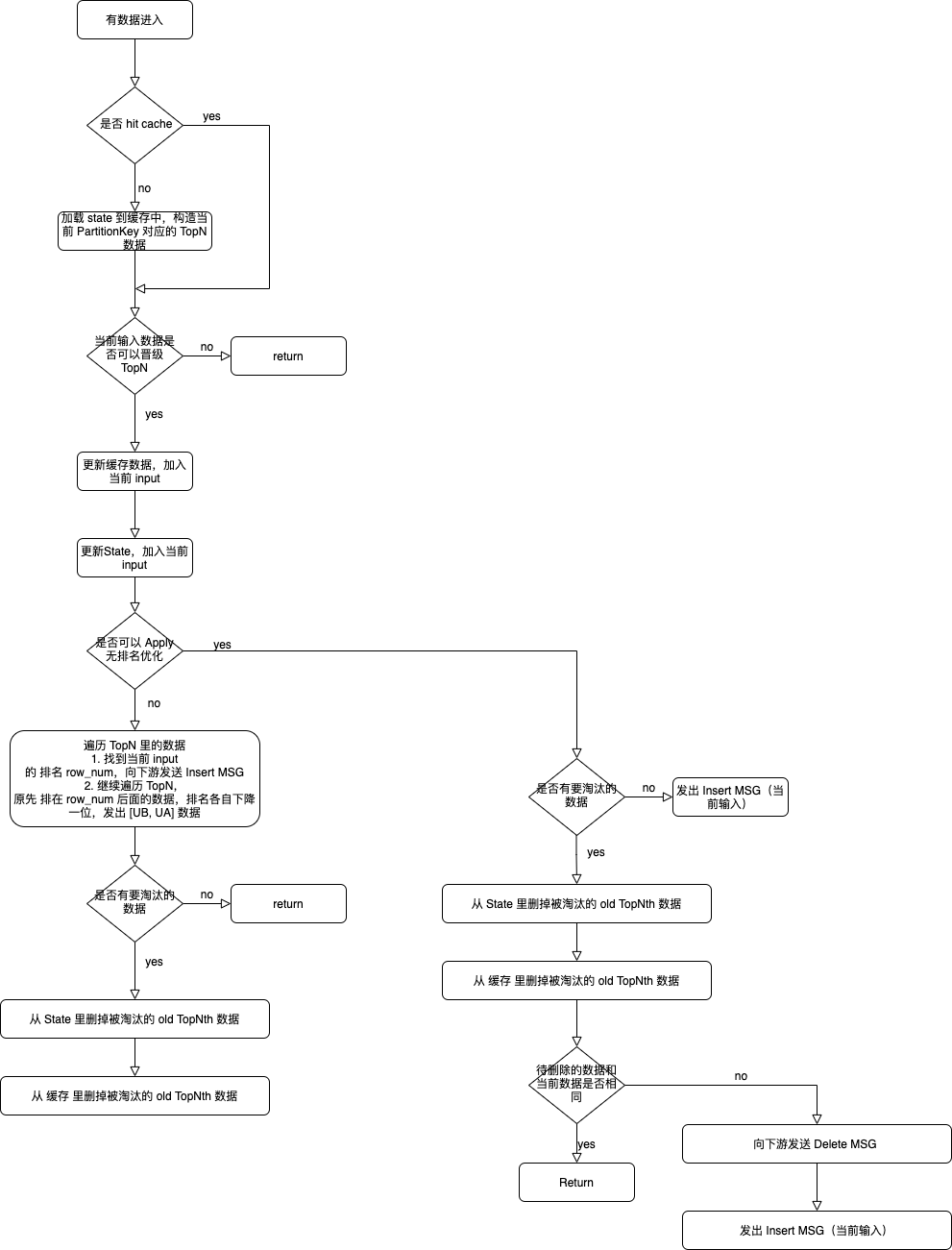
State 读写时机
平时和Cache 交互,只在下面三种情况才和 State 交互
- 没有命中 Cache 的时候,需要从 State 里加载数据
- 做 Checkpoint,需要把 Cache 里的数据刷到 State里
- LRUCache 满了要淘汰 Oldest数据,需要把 Cache 的数据刷到 State 里
处理流程
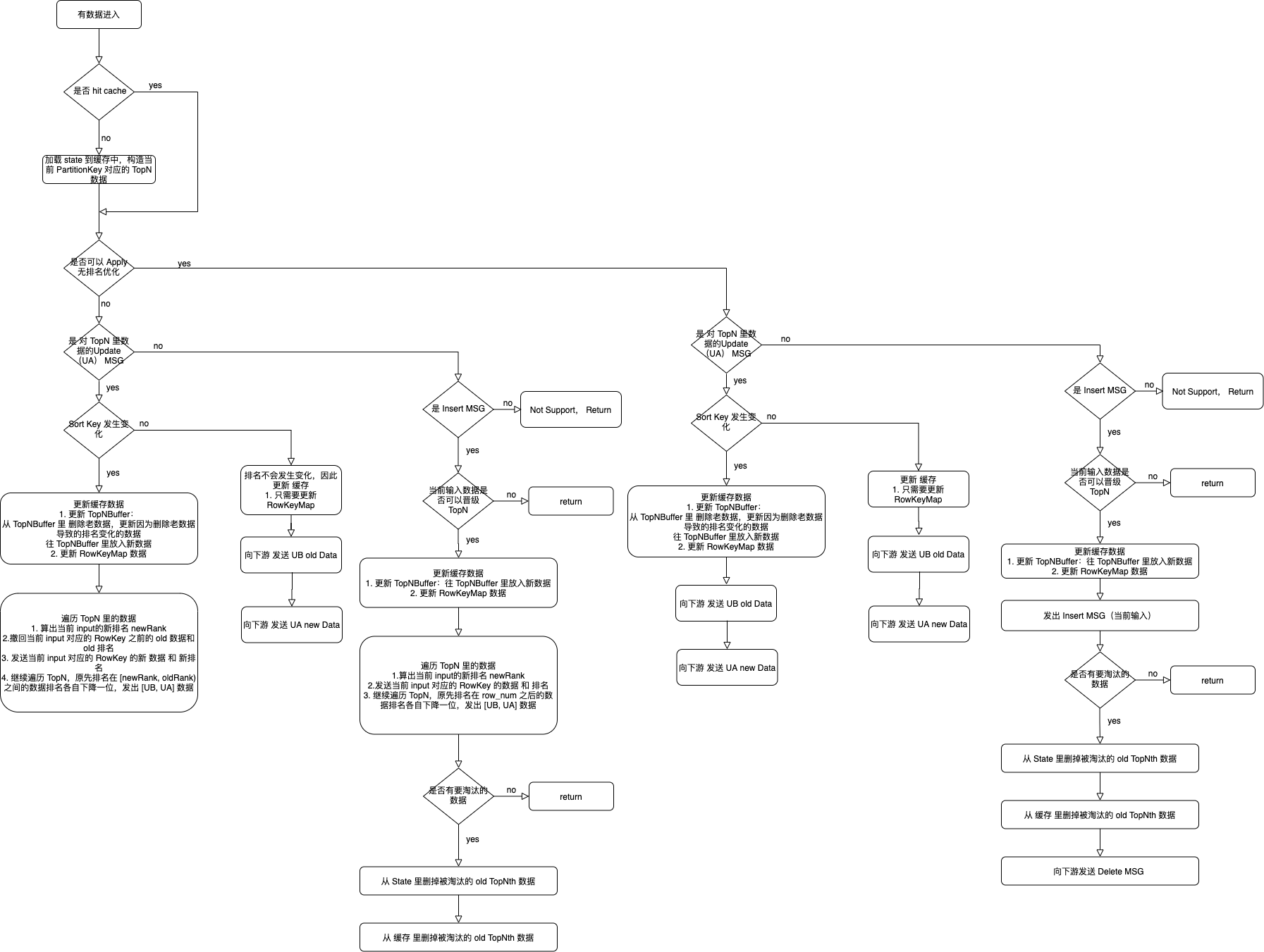
RetractableTopNFunction
内存 Cache 设计
无 Cache
State 设计
存储的内容
存储了所有的输入数据
存储格式
1 | MapState<RowData, List<RowData>> // (Key 是 SortKey,Value 是 Records 列表) |
State 读写时机
Per Record 和 State 交互。
处理流程